Today, at the WorldWide Data Vault Consortium (WWDVC) event in Stowe, Vermont, I launched the Data Vault Alliance, a new global community which seeks to unite Data Vault experts, vendors and practitioners and share best practices for Data Vault 2.0 with organizations worldwide. One of the primary reasons that I founded the Alliance was to provide IT practitioners with the right education, tools and resources to be successful with Data Vault 2.0 and reap its benefits for the organizations they serve as quickly as possible.
But what is a Data Vault, and why should organizations consider it? My colleague Michael Olschimke, CEO at Scalefree, discussed this in a recent webinar with WhereScape and here’s a quick explanation he shared:
A Quick Introduction
At a basic level, a Data Vault consists of three key categories of information:
- Hubs – unique lists of business keys
- Links – unique lists of relationships
- Satellites – descriptive data over time
The hub sits at the heart of the methodology and is then connected via links to other hubs or satellite information. This satellite information is where all the “color” of useful data is held – including historical tracking of values over time. Examples of satellite information could include customer data, location data or individual information streams from different business units.
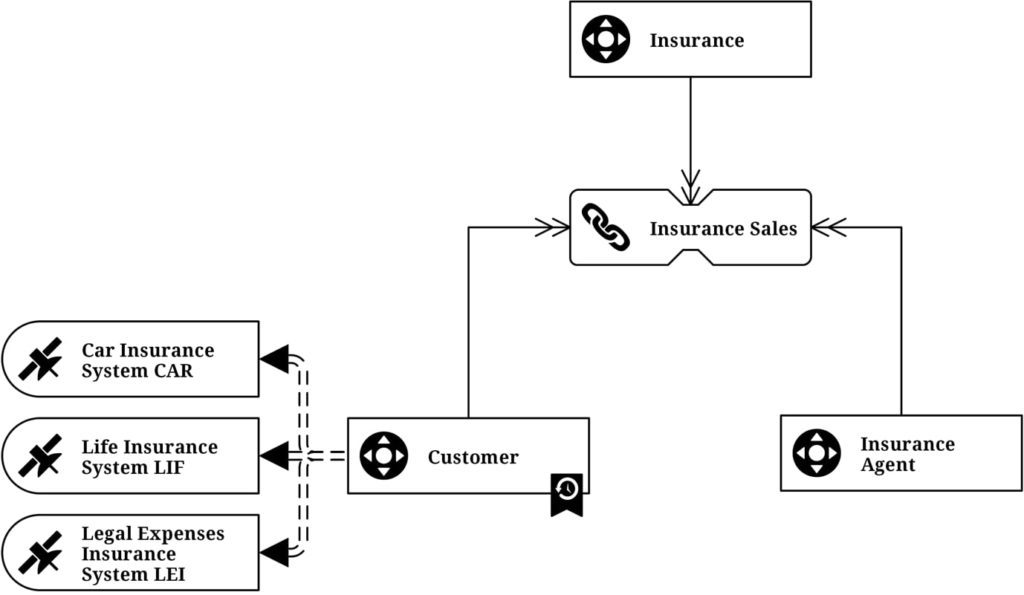
Together, combinations of these categories form the “network” of a Data Vault, a way of connecting together bits of information in a flexible, repeatable way that can enable a consistent development stream. At its core, using Data Vault 2.0 methodology helps businesses fuse together many different data streams from varying sources, in such a way as can deliver actionable, useable information for end users.
How Does a Data Vault Process Information?
The usual workflow for a Data Vault environment follows four stages:
- Data is loaded from the source into either a relational data system or a data lake
- Data is then broken down into individual “lego brick” components, and then built in a more targeted manner using simple ETL driven by metadata
- One information is regrouped, enterprise business rules can be applied to turn these individual data fragments into useful information
- Lastly, an overarching schema is applied – whether that is a star schema or a snowflake schema or something else entirely, this create the basis to overlay a dashboard tool ready to present back insights
At the end of this process, a fully formed Data Vault provides a solution that is almost “self-service business intelligence”, as well as a raw data stream where power users can create and write back solutions to their own user area, without affecting the core IT data warehouse. The question is, how do we get there?
Data vault automation can play a critical role here. As this workflow remains a constant repeatable process in the Data Vault, it is perfect for applying automaton to help organizations realize the benefits, faster. WhereScape® Data Vault Express™ offers exactly this capability – allowing businesses to achieve scalability and data consistency, as well as reaping the benefits of Data Vault 2.0 sooner.
For those wishing to learn more about Data Vault 2.0, and deepen their expertise in Data Vault 2.0 modeling, methodology and architecture, the Data Vault Alliance can provide you with access to world-class training, professional development certifications, organizational assessment tools, directories of authorized Data Vault 2.0 vendors and mentoring opportunities. You can view this video to learn more about the Data Vault Alliance. I encourage you to take a look at this new online community today.
And for those of you attending the WWDVC, I hope the knowledge and experience our presenters share at this week’s event provide you with many practical ideas to take back and implement within your organizations. It’s an exciting time for the Data Vault community, and if you aren’t yet applying Data Vault 2.0, now is the perfect time for you to learn more and evaluate if it is right for your organization.


