
No single data automation tool can meet every data need.
Some excel at real-time operational flows, others at lifecycle automation, others at democratizing analytics or regulatory stewardship. The right choice is as much about features as it is about fit for teams, sector, data complexity, and how deep automation needs to go.
This comparison breaks down how WhereScape, Estuary Flow, Alteryx, Qlik Replicate, and Talend Data Fabric deliver on automation, governance, and platform support. Each tool comes with a strengths profile, real-world tradeoffs, and distinctive sector and stack coverage.
Use this comparison of data automation tools as a blueprint to match architectural strengths and limitations to the realities of each environment.
| Tool | Automation scope | Governance and lineage | Platform support | Sector fit/notes | Top limitations | Standout features and benefits |
| WhereScape | End-to-end data warehouse lifecycle automation; ELT/ETL, metadata-driven codegen, visual modeling | Automated documentation, full versioned lineage, role-based security, integrates native compliance and maintains audit-ready environment. | Snowflake, Databricks, Microsoft Fabric, MS SQL Server + 15 other platforms (on-prem/hybrid/migrations fully supported) | Regulated environments: finance, healthcare, govt, education, manufacturing | UI/UX learning curve for model-driven methods | Metadata-driven automation, full code gen, rapid ETL/ELT, integrated scheduling, full data vault and audit trail support |
| Estuary Flow | Real-time batch/streaming, exactly-once delivery, 200+ connectors, in-pipeline SQL/TypeScript | Lineage tracing, RBAC, real-time validation, zero-trust, and mTLS security | Snowflake, BigQuery, Redshift, Oracle, MySQL, Mongo, Elastic, S3, SaaS, streaming, ML targets | Real-time ops: CPG, fintech, edtech, energy, SaaS, telecom | Large-scale IoT/streaming bottlenecks possible | Exactly-once, idempotent streaming, extensive high-quality connector library, supports both native and open-source connectors, real-time in-pipeline transformations, auto schema evolution |
| Alteryx | Low-code, drag-and-drop workflow automation, deep spatial analytics | Data cataloging (Alteryx Connect), audit trails, CRM/SSO, profiling and stewardship tools | Snowflake, Redshift, Synapse, BigQuery, SQL Server, Oracle, Tableau, Power BI, Salesforce, hybrid | Analytics, BI, spatial UX: retail, public sector, supply chain | Sluggish UI at scale, weak git/version control | Industry-leading spatial analytics, interactive mapping, comprehensive no-code automation, strong data preparation UI |
| Qlik Replicate | Log-based CDC, high volume, agentless real-time replication, monitoring UI | Technical lineage, detailed change/audit logs, FIPS-compliant encryption | Snowflake, Redshift, BigQuery, Oracle, DB2, SAP, S3, Hadoop, Windows/Linux, on-prem/cloud/hybrid | Real-time replication: banking, healthcare, supply chain | Limited business/visual lineage catalog | Agentless log-based CDC, in-memory change streaming, supports diverse cloud and on-prem ecosystems, easy CDC monitoring |
| Talend Data Fabric | Modular pipeline orchestration, hundreds of connectors, Trust Score™, strong profiling | End-to-end metadata/tracing, data stewardship, customizable dimensions, audit/reporting | Snowflake, Redshift, BigQuery, Azure, Oracle, SAP, Kafka, IoT, SaaS, cloud/on-prem/hybrid | Multi-cloud integration: retail, healthcare, utilities, technology | Complex/hybrid arch requires oversight; higher TCO | Metadata-driven automation, Full code generation, Rapid ETL/ELT, integrated scheduling, full data vault and audit trail support |
1. WhereScape: End-to-End Data Automation for Warehouses
WhereScape is a data automation tool that delivers end-to-end lifecycle coverage for designing, building, orchestrating, and managing data warehouses and products.
Best for: Cross-functional data teams of all sizes working in legacy and/or complicated systems.
Sector coverage
- Financial services: Credit unions, regional banks, lenders, and asset managers
- Healthcare insurance: Providers, payers, hospitals, and clinical systems
- Manufacturing: Large manufacturing organizations
- Education: Higher education systems and school districts
- Government: State and local government, state-owned organizations
Supported platforms
- Cloud data warehouses: Snowflake, Databricks, AWS, GCP, Oracle, Teradata, Azure, PostgreSQL and Microsoft Fabric
- On-prem databases: Microsoft SQL Server, Oracle and PostgreSQL
- Hybrid deployments: Full support for migrations and hybrid deployments
- Native automation: ELT/ETL, schema generation, and code adaptation to target
Standout features
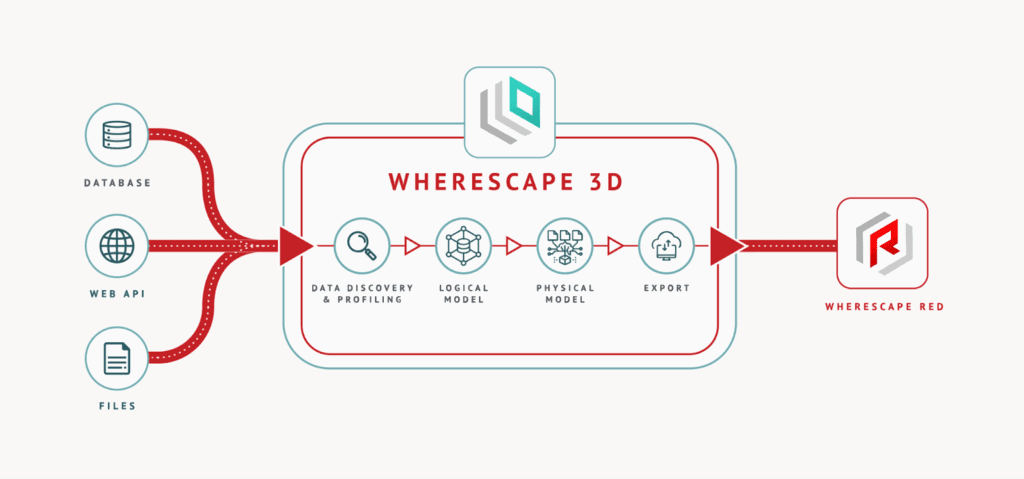
- Metadata-driven automation: WhereScape automates the entire lifecycle of data warehouse development in a single, metadata-centric environment.
- Discover: WhereScape automatically examines source systems, profiling structure, data quality, and content, to help users quickly understand inputs and reduce surprises downstream.
- Design: Build conceptual and physical data models visually with WhereScape 3D. 3D generates blueprints directly from requirements and captures entities, relationships, and business logic as metadata. This eliminates the need for hand-drawn diagrams and manual translation steps.
- Develop: WhereScape takes the initial metadata model and automatically generates all the tables, transformations, load processes, and platform-specific code, so designs automatically turn into an operational environment.
- Deploy: WhereScape automatically handles the technical translation, sequencing, and logging of data warehouse deployments. This data automation tool uses the metadata to generate and push the right code to the target environment.
- Operate: WhereScape automates scheduling, operational monitoring, logging, and audit trails, which makes workflow oversight part of the metadata layer.
- Enhance: When business or technical requirements change, use WhereScape’s wizard-driven patterns and best-practice templates to adjust data vault architecture. Then, WhereScape automatically regenerates the necessary, platform-specific code, updates all metadata and data lineage, and redeploys the solution while preserving compliance and full audit history.
Data quality, security, lineage, and compliance
- Fully documented history: Every data flow, transformation, and model adjustment is automatically documented in detail. Changes are versioned and linked to users.
- End-to-end lineage and traceability: WhereScape tracks data lineage from source to destination, capturing how every field, table, and transformation evolves. Lineage details are accessible through the UI and exports.
- Automated data quality and validation: The platform integrates data testing, schema validation, and anomaly detection directly into the automation lifecycle. Validation rules and schema comparisons are enforced with every deployment or change.
- Role-based security: Get granular control over who can access, modify, or deploy data projects using detailed, role-based permissions.
- Native security: WhereScape leverages and extends the native security models of platforms, allowing users to inherit SOC 2, HIPAA, and GDPR compliance automatically.
Limitations
- Interface depth: If teams are less familiar with metadata-driven or model-based workflow, expect a UI/UX learning curve.
2. Estuary Flow: Real-Time Streaming and Data Integration
Estuary Flow is a data automation tool for real-time complex data movement and integrations.
Best for: Small-to-midsize teams needing near real-time access to operational data and analytics.
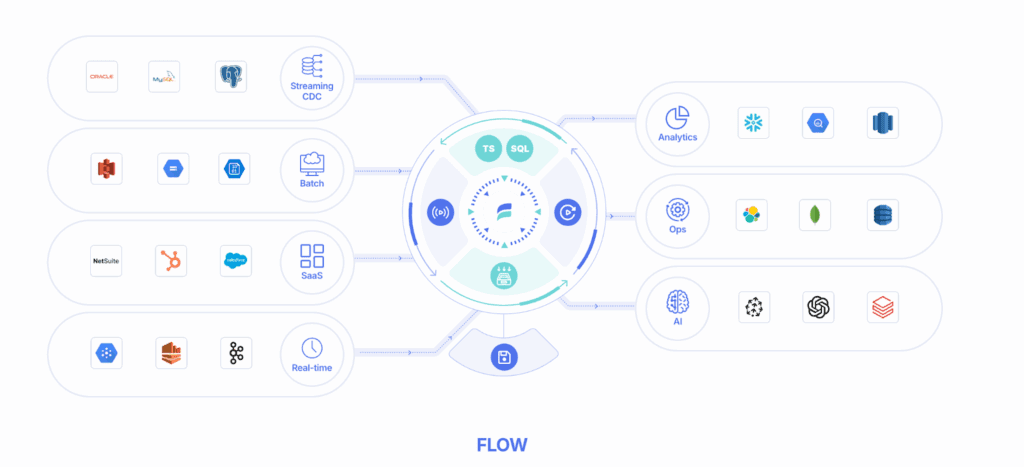
Sector coverage
- Education: Higher education, school districts, edtech vendors, and learning management
- Financial services: Credit unions, lenders, asset managers, payments, risk, and fraud
- Public sector and government: State, local, civic tech, and grant data
- Telecom: Telecom analytics, customer operations, and network providers
Supported platforms
- Cloud data warehouses: Snowflake, BigQuery, Redshift
- On-prem databases: Oracle, MySQL, PostgreSQL, MongoDB, Elastic, and DynamoDB
- Cloud storage/object storage: Amazon S3, Google Cloud Storage, and Azure Blob Storage
- SaaS: Salesforce, HubSpot, and NetSuite
- ML and analytics: Databricks and Pinecone
- Streaming and messaging: Kafka, PubSub, and Kinesis
- Hybrid deployments: Moves data from and to all major endpoint types
- Native automation: 200+ connectors for automated data integration
Standout features
- Exactly-once delivery with low latency: Flow coordinates persistent logs, checkpoints, and transactional connectors so every event is processed once and only once. This spans batch and streaming workloads and covers source and destination.
- Checkpoints: Flow commits both the data to the destination and its own checkpoint in a recovery log as a single atomic operation. If a failure occurs mid-pipeline, Flow can resume from the last committed checkpoint. For each destination, it leverages either full transactional materialization or a delta-update mode, adapting to the system’s capabilities.
- Idempotency and atomicity are built in: No batch is considered delivered until both the datastore and Flow’s recovery log agree on the commit.
- Real-time, in-pipeline SQL/TypeScript transformations: Estuary Flow lets users reshape, join, filter, and enrich data using SQL or TypeScript transformations directly within the pipeline, in real time as data moves, not after it lands. This eliminates the need for post-load batch jobs and extra orchestration.
Data quality, security, lineage, and compliance
- Data quality: Automated schema inference and management, continuous validation and test cycles, built-in resilience against late or missing data
- Security: Full RBAC, mTLS, Zero-trust, regional data plane, and controls at rest and in transit
- Lineage: Detailed lineage tracing
- Compliance: Process and store data in regions or the cloud, ensuring regulatory alignment for GDPR, HIPAA, etc.
Limitations
IoT and large-scale streaming: While this data automation tool covers late and out-of-order event handling, teams can still hit bottlenecks with some cloud warehouse merge operations like Snowflake MERGE.
3. Alteryx: Low-Code Data Automation and Spatial Analytics
Alteryx is a low-code, unified analytics and data automation tool that streamlines data preparation, blending, analytics, and reporting.
Best for: Mid-to-large analytics, BI, and data operations teams that have a mix of technical and non-technical users looking for repeatable, complex spatial analyses.
Sector coverage
- CPG and retail: Merchandisers, supermarkets, and retail chains
- Education: Higher education, universities, and school districts
- Financial services: Banking, insurance, investment, compliance, and portfolio management
- Healthcare: Hospitals, clinical organizations, and healthcare providers
- Manufacturing: Discrete and process manufacturers, supply chain ops
- Travel and hospitality: Large operators
Supported platforms
- Cloud data warehouses: Snowflake, Redshift, Azure Synapse, and BigQuery
- On-prem databases: SQL Server, Oracle, MySQL, and PostgreSQL
- Cloud storage/object storage: AWS S3 and Azure Blob
- SaaS: Salesforce and Google Analytics
- BI and reporting: Tableau, Power BI, and Qlik
- Hybrid deployments: Supported; depending on connectors
- Native automation: Drag-and-drop automation,
Standout features
Deep spatial analytics: Alteryx delivers advanced spatial analytics by ingesting, enriching, and analyzing spatial data through no-code, drag-and-drop workflows.
Team connect to spatial and tabular sources like shapefiles, spreadsheets, and cloud platforms. A built-in suite of spatial tools in Alteryx Designer geocodes addresses, creates lat/lon points, performs true spatial joins, models drive-time and trade areas, and executes route or network optimization as configurable nodes in a workflow.
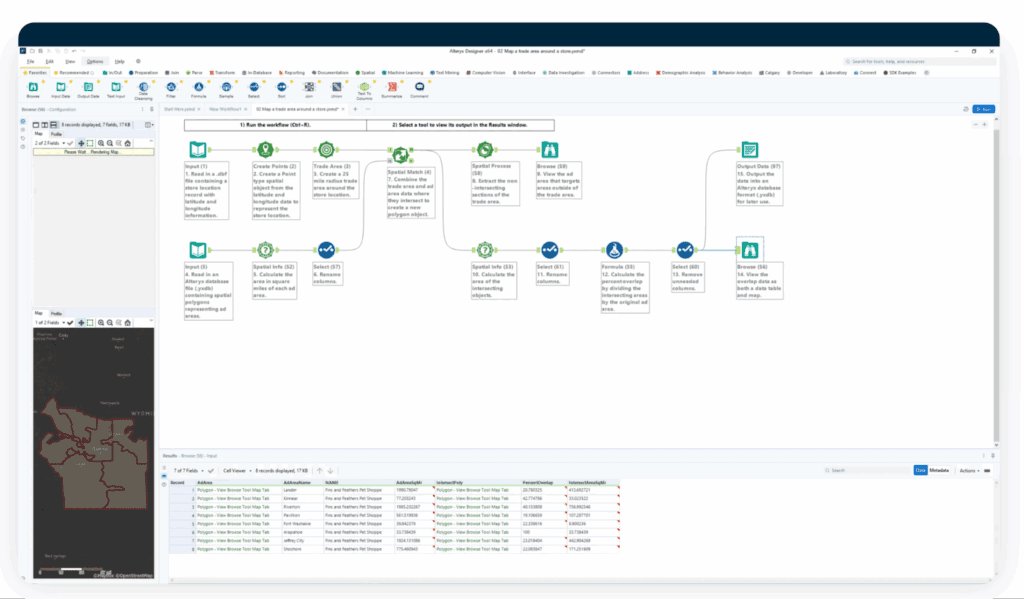
Data quality, security, lineage, and compliance
- Data quality: Automated and scheduled audits and built-in cleansing, deduplication, standardization, and error detection
- Security: RBAC, encrypted credentials, and granular workflow access controls. Supports single sign-on and pass-through authentication
- Lineage: Data cataloging and lineage tracking through Alteryx Connect. Asset sharing, full workflow histories, metadata management, and audit trails
- Compliance: Customizable data stewardship workflows and controls
Limitations
- GUI-heavy design: The UI can become sluggish, especially at scale or with many users connected to large databases.
- Weaker versioning and collaboration: Especially for users of modern, Git-based CI/CD.
4. Qlik Replicate: Change Data Capture (CDC) and Real-Time Replication
Qlik Replicate is a data automation tool built for real-time, high-volume data replication, ingestion, and streaming.
Best for: Mid-to-large teams responsible for cross-platform data movement and need real-time or near-real-time analytics, reporting, or cloud migration.
Standout features
Log-based change data capture (CDC): Qlik Replicate reads directly from a database’s transaction logs and captures all inserts, updates, and deletes as soon as they happen.
The process is automatic and agentless, so there is no need to install software on each source database, which keeps production systems safe from extra load and possible risks.
This CDC method can be used across platforms, mainframe systems, and cloud databases, where changes can be streamed in real time, regardless of vendor or environment.
Qlik Replicate processes changes in-memory and pushes them downstream without delay. This means analytics, reporting, and recovery systems have fresh, accurate data with minimal lag. Teams can monitor and control all CDC jobs through a web interface.
Sector coverage
- CPG and retail: Supermarkets, retail chains, specialty retail, and distribution centers
- Financial services: Commercial and investment banking, capital markets, and payment processors
- Healthcare: Integrated delivery networks, pharma R&D, medical device, and hospital systems
- Manufacturing: Aerospace, defense, electronics, and semiconductors
- Technology: Managed service providers and custom software, and IT services
Supported platforms
- Cloud data warehouses: Snowflake, Amazon Redshift, Google BigQuery, Azure Synapse, Teradata, and IBM Netezza
- On-prem databases: Oracle, SQL Server, DB2, PostgreSQL, MySQL, and SAP
- Big data: Hadoop HDFS
- No SQL/non-relational: MongoDB
- Cloud storage/object storage: Amazon S3 and S3-compatible storage
- Cloud-managed databases/services: AWS (all major DBs), Azure (SQL, CosmoDB, etc.), and Google Cloud (Cloud SQL, BigQuery, etc.)
- Hybrid deployments: Full support for hybrid and migrations
- Native automation: Replication and change data capture
Data quality, security, lineage, and compliance
- Data quality: Validation checks on data replication. Focuses on integrity and reliability during movement, with less emphasis on deep profiling or data cleansing
- Security: End-to-end encryption for data in transit, secure data transfers, and strong separation of duties. Supports secure credentials and controlled access
- Lineage: Tracks source-to-target movement through replication logs and technical traceability.
- Compliance: FIPS-compliant. Detailed audit logs
Limitations
- Reporting: Does not provide a business-facing lineage catalog or visual data lineage
5. Talend Data Fabric: Multi-Cloud Data Automation and Trust Score™
Talend Data Fabric is a unified data automation tool that transforms, validates, and delivers data across multiple platforms and at scale, in a modular, low-code approach.
Best for: Mid-market teams dealing with fragmented, multi-source data environments who need data integration and sharing in multi-cloud architectures.
Sector coverage
- CPG and retail: Retail chains, e-commerce, food and beverage, and supply chain
- Financial services: Banking, insurance, and asset management
- Healthcare: Providers, payers, pharmaceuticals, medical devices, and clinical integration
- Manufacturing: Discrete, process, and automotive manufacturing
- Public sector and government: State and local
- Technology: IT, digital integration, SaaS, and cloud platforms
- Telecom: Customer data and analytics
Supported platforms
- Cloud data warehouses: Snowflake, Redshift, BigQuery, Azure Synapse, and Teradata
- On-prem databases: Oracle, SQL Server, MySQL, PostgreSQL, DB2, and SAP
- Big data: Hadoop and Spark
- No SQL/non-relational: MongoDB and others
- Cloud storage/object storage: AWS S3, Azure Blob, and Google Cloud Storage
- SaaS: Salesforce, HubSpot, NetSuite, and others
- ML and analytics: Databricks and integrations with ML frameworks
- Streaming and messaging: Kafka, Amazon Kinesis, Azure Event Hubs, Google PubSub, Apache Pulsar, RabbitMQ, and MQTT
- IoT/streaming data sources: Full streaming protocol and connectors support
- Hybrid deployments: Full support on-prem, cloud, multi-cloud, and hybrid
- Native automation: Pipeline orchestration, no-code/low-code tools, and hundreds of connectors
Standout features
The Talend Trust Score™ gives a real-time, unified metric that reflects how much trust can be placed in any dataset in any environment. It scores six data dimensions:
- Data quality
- Completeness
- Lineage
- Documentation
- Usage statistics
- User feedback.
The score is automatically updated as data flows and changes. This means an up-to-date, explainable measure of data reliability, regardless of the source or usage of data. When browsing datasets, the score will be present as a visible icon, allowing the prioritization of high-confidence data.
In the background, Talend Trust Score™ analyzes schema consistency, field-level profiling, rule validation, and data popularity through access frequency, and even business or IT user certification. If a score drops, Talend flags problem areas and recommends remediation actions like fixing nulls, resolving invalid values, improving completeness, or enhancing documentation.
Data quality, security, lineage, and compliance
- Data quality: Native profiling, cleansing, deduplication, and enrichment functions. Profiling visualizations, regular expression matching, and custom quality indicators.
- Security: End-to-end encryption and masking components secure data in transit and at rest. Role-based access controls. Audit trails log access and changes throughout pipelines. Data encryption options (AES-GCM, Blowfish) are configurable to fit policy requirements.
- Lineage: End-to-end tracked and visualized. Metadata repository supports documentation and traceability.
- Compliance: Supports GDPR, HIPAA, and industry regulatory frameworks. Automated reporting and cataloging.
Limitations
- Complex deployments and real-time streaming across hybrid environments may require architectural oversight.
- Costs rise as data volumes and advanced features grow.
- Advanced analytics and ML require external integration.
How to Choose the Best Data Automation Tool for Your Organization
You’ll always be weaving together capabilities, regulatory demands, and operational realities to navigate the friction points that emerge in your environment.
So, you have to build a stack that’s technically stable and is also designed to flex as your data and environment priorities shift.
WhereScape can anchor your automation layer by managing today’s data lifecycle complexity to ensure you have the auditability, agility, and governance muscle to address tomorrow’s questions without adding fragility or technical debt.
If you’re architecting for both operational lift and long-term resilience, try WhereScape in your environment.
See for yourself how this agile technology provides full lifecycle automation that reduces technical debt and enforces compliance, positioning your team to adapt confidently as new tools and challenges arrive.
FAQ
What are data automation tools used for?
Data automation tools are platforms that streamline how data is collected, transformed, and delivered. They reduce manual processes, improve data quality, and ensure governance across multiple platforms. Teams use them to connect systems, enforce compliance, and make analytics more reliable.
Which data automation tool is best for real-time data streaming?
Estuary Flow is designed for real-time streaming with exactly-once delivery and extensive connector support. It’s well-suited for industries like fintech, telecom, and energy where latency and continuous data flow are critical.
What is the most comprehensive data automation tool for governance?
WhereScape provides end-to-end governance with full versioned lineage, automated documentation, and compliance integration. It’s a strong fit for highly regulated sectors like finance, healthcare, and government.
How do I choose between Alteryx and Talend Data Fabric?
Choose Alteryx if your team needs no-code workflow automation and advanced spatial analytics. Talend Data Fabric is a better fit if you operate in multi-cloud environments and need strong profiling, data quality scores, and flexible orchestration.
What industries benefit most from Qlik Replicate?
Qlik Replicate is widely used in cases where real-time replication and change data capture (CDC) are essential. It ensures fast, reliable data movement without adding stress to production systems.
Are data automation tools worth the cost for smaller teams?
Yes, but the right fit matters. Smaller teams often see ROI from tools like Estuary Flow, which simplify integration and reduce manual pipelines. Larger platforms like Talend or WhereScape may require bigger initial investments but deliver stronger long-term governance, scalability and price clarity as there are no ‘hidden costs’ that typically arise in the use of many other platforms..


